What is Failover and How is it Related to High Availability?
Using Network Redundancy and Load Balancing to Ensure Application Availability
Failover, in which the functions of a failed or offline system, component, or network are switched automatically to a secondary backup, is a key element of high availability. By providing both system-level redundancy and network redundancy, failover ensures that normal operations can continue even in the event of problems or scheduled maintenance. Failover is generally enabled through devices such as an application load balancer or an application delivery controller.
Ensuring High Availability through Failover and Network Redundancy
To ensure acceptable service for users and reliable support for the business, organizations need their applications to be available, performant, and fault-tolerant at all times. This requirement is referred to as application availability, and evaluated using key performance indicators (KPIs) such as overall or timed application uptime and downtime, number of completed transactions, responsiveness, and reliability. Real or perceived failures such as consistent errors, timeouts, missing resources, and DNS lookup errors are also taken into account.
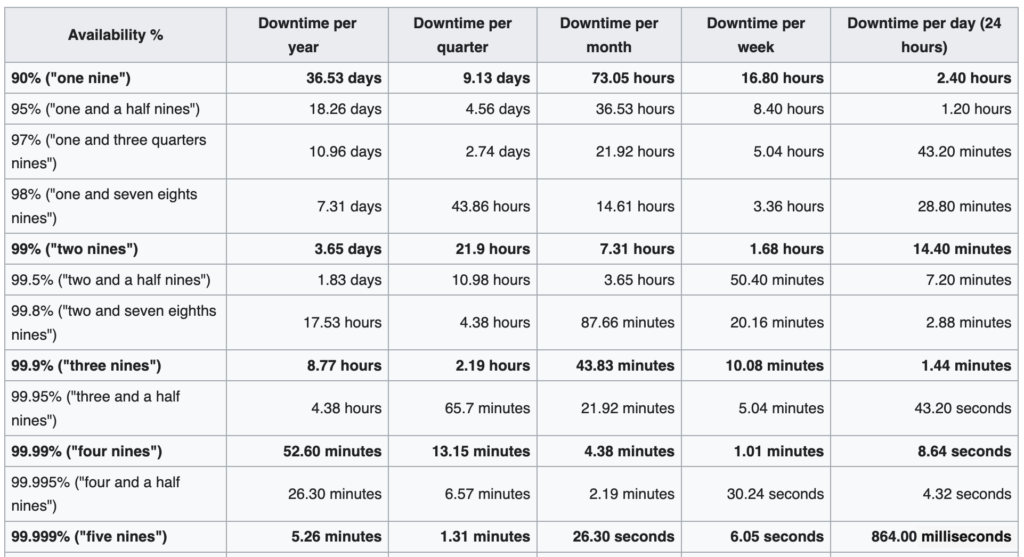
In situations where reliability is especially critical, organizations strive to meet a demanding standard for high availability. This is often defined as “five 9s” (99.999 percent), in which operations maintain consistent operations with an extremely low error rate for a long period of time. To provide high availability, systems must be designed to avoid single points of failure so that individual problems—which are inevitable in even the best computing environments—will not impact users. To this end, high availability architectures typically include redundant backup systems as well as mechanisms to switch over to these secondary components or networks in the event of a problem. To avoid disruption, this failover process must be as rapid and transparent to the user as possible.
Network redundancy is one of the most important parts of a high availability strategy. By installing redundant network devices, equipment, and communication mediums within network infrastructure, organizations can enable rapid failover to ensure that essential network communications will continue uninterrupted even if a network device or path becomes unavailable. Network redundancy is typically achieved through standby routers and switches, which can quickly reroute network traffic through alternate network paths to keep network communications and services available. Comprehensive network redundancy can also encompass power sources such as battery backups or generators, data replication, and geographic diversity to protect against a broad range of natural disasters and other unexpected events.
Similar to the role of backup network devices to enable network redundancy, high availability clusters enable failover for the servers that support application delivery. By deploying servers in redundant pairs or including a single spare server in a larger group, organizations can quickly shift application services from a failed server to a backup with minimal downtime and disruption.
The Role of Application Load Balancers and Application Delivery Controllers in Failover
Within a high availability architecture, failover is provided by a load balancer or application delivery controller. In either case, the load balancing function distributes incoming application traffic across multiple compute nodes, such as physical or virtual servers, in order to ensure that no single server bears too much of the demand. This can include redistributing traffic from a failed device, virtual machine (VM), or cloud instance across other members of its cluster, or using failover to switch its traffic and tasks to a secondary backup server. In addition to improving application responsiveness and availability, the health checking, load balancing, and failover provided by an application load balancer or server load balancer can also help organizations withstand distributed denial-of-service (DDoS) attacks.
An application load balancer performs load balancing at the application layer, or Layer 7 of the Open Systems Interconnection (OSI) Reference Model for networking, making routing decisions based on detailed information such as the characteristics of the HTTP/HTTPS header, message content, URL type, and cookie data. A server load balancer performs a similar role at the transport layer, or Layer 4, using the TCP and UDP protocols to manage transaction traffic based on a simple load balancing algorithm and basic information such as server connections and response times. Global server load balancing (GSLB) performs a similar function on a broader scale across multiple data centers and/or clouds. An L4-7 load balancer manages traffic based on a set of network services across ISO layers 4 through 7 that provide data storage, manipulation, and communication services.
As an alternative to a dedicated application load balancer or server load balancer, the load balancing function can also be provided by an application delivery controller, alongside other functions, to securely deliver customer-facing applications at enterprise scale such as performance acceleration, analytics, and firewall. Deployed between an organization’s web servers and end users in a hardware, virtual, cloud, bare metal, or container form factor, an application delivery controller helps organizations handle high transaction volumes with minimal delay while protecting application servers. As both enterprise environments and workforces have become more widely distributed, application delivery controllers have become one of the most important elements of the infrastructure, helping organizations ensure optimal performance with full security wherever people work. By using an application delivery controller with integrated L4-7 load balancing functionality, organizations can simplify their infrastructure, streamline management, and enhance the effectiveness of both application delivery and load balancing.
For a high availability strategy to be effective, organizations need a way to determine when a problem or failure calls for automatic failover. Performed by either a load balancer or an application delivery controller, this health checking function consists of probes to servers, network devices, and other components to evaluate their availability and capture performance metrics such as throughput, traffic rates, percent of error traffic over range, number of good SSL connections, average application server and client-side latency, and response time for specific SQL database queries. If a server responds successfully to a given number of probes, it is considered healthy, and remains eligible to receive new requests. An unhealthy device can be flagged for attention by IT, while automatic failover switches operations to a backup device or redistributes traffic across the remaining members of the cluster.
How A10 Networks Supports Failover for High Availability
The A10 Networks Thunder® ADC application delivery and load balancing solution ensures high availability and rapid failover with little or no downtime by continuously monitoring server health. The solution’s health checking functionality is part of a rich set of load balancing, server load balancing, and global server load balancing capabilities.
Related Assets
- What is Application Availability? (Video)
- Peruvian Air Force Ensures Private Cloud Application Availability with Thunder ADC (Case Study)
- Turner Industries Boosts Application Availability with Virtual Load Balancing (Case Study)
- Global Investment Firm Ensures Application Availability with Thunder ADC (Case Study)