The Ultimate Guide to LLM Security in 2026

Large language models are no longer experimental tools running in isolated environments. They are embedded directly into production systems across enterprises: customer support automation, developer copilots, internal knowledge assistants, analytics engines, workflow automation platforms, and security orchestration tools.
As adoption accelerates, so does exposure.
This guide outlines how LLM security works, why it matters, the dominant threats, the right protection architecture, and how organizations should evaluate LLM security tools in 2026.
Key Takeaways
- LLM security is the practice of protecting large language models, inference endpoints, APIs, and connected enterprise systems from prompt injection, data leakage, model manipulation, and infrastructure abuse.
- Unlike traditional applications, LLMs systems interpret natural language dynamically, combine context sources at runtime, and may trigger automated downstream actions. That combination creates a fundamentally different cybersecurity challenge.
- Treating LLMs like normal web apps leaves gaps; enterprise LLM security requires architectural controls, runtime enforcement, and AI‑aware threat detection.
What Is LLM Security?
LLM security refers to the technologies, policies, and architectural controls designed to protect large language models and their surrounding ecosystems from misuse, compromise, and data exposure.
In practical terms, LLM cyber security addresses:
- Prompt injection and instruction override
- Sensitive data leakage through model outputs
- Unauthorized API execution
- Retrieval system manipulation
- Inference endpoint abuse
- Infrastructure-level attacks on AI workloads
However, defining LLM security purely by threat categories understates its scope.
Large language models are probabilistic systems. They do not execute fixed, deterministic code paths. Instead, they generate responses by weighting context across system prompts, user inputs, retrieval layers, memory state, and external data connections. This dynamic behavior introduces interpretive risk.
Traditional security models assume deterministic behavior. LLM application security must assume contextual variability.
Because of this shift, LLM security is not simply a subset of web application security or API protection. It is an emerging discipline that requires AI-specific enforcement mechanisms.
Why LLMs Redefine the Cybersecurity Model
LLMs introduce structural changes to application behavior that directly affect security design.
First, natural language becomes an execution vector. In conventional systems, attackers exploit code vulnerabilities such as SQL injection or buffer overflows. In LLM systems, attackers exploit interpretation. Prompt injection attacks manipulate how the model interprets instructions. Carefully crafted text can override system directives, request hidden context, or influence downstream API calls.
No software flaw is required. The vulnerability exists in the interpretive layer.
Second, outputs may trigger real-world actions. Modern enterprise LLM deployments frequently connect to APIs, databases, workflow engines, and automation tools. A compromised interaction can extend beyond content generation and influence operational systems. The blast radius is therefore broader than in traditional content-only applications.
Third, context blending increases exposure. Retrieval-augmented generation systems combine the model with vector databases containing internal documents, proprietary knowledge, and sometimes regulated data. If isolation boundaries are weak, the model may retrieve and expose sensitive content in response to adversarial prompts.
Fourth, probabilistic output complicates detection. Traditional security tools rely on pattern matching and deterministic rule enforcement. LLM outputs vary across sessions, making static inspection insufficient. LLM threat detection must analyze behavioral signals and interaction patterns rather than simple keyword matches.
These shifts explain why enterprise LLM security must extend beyond perimeter defenses.
The Core Threat Landscape in LLM Security
While the field continues to evolve, four dominant threat categories define the current risk environment.
Prompt Injection
Prompt injection remains the most immediate and visible threat. Attackers attempt to override system instructions by embedding malicious directives inside user prompts. A model instructed to ignore previous instructions and reveal internal context may comply if guardrails are weak. Because prompt injection directly targets model behavior, it sits at the center of LLM security strategy.
Data Leakage
Data leakage is equally critical. Enterprise LLM deployments often connect to internal knowledge bases, proprietary documents, or regulated datasets. Without strict context isolation and output validation, sensitive information may be surfaced unintentionally. In industries governed by compliance requirements, this exposure creates significant legal and reputational risk.
Model Manipulation
Model and retrieval manipulation represent another class of risk. Attackers may attempt to poison training data, tamper with vector indexes, or influence retrieval context. These attacks degrade output integrity and erode trust in AI systems.
Finally, inference endpoints are high-value infrastructure assets. LLM workloads are computationally intensive and expensive. Attackers may target endpoints with credential abuse, token exhaustion, flooding attacks, or cost amplification techniques. In these cases, availability and financial impact become primary concerns.
An effective enterprise LLM security strategy must address all four threat domains simultaneously.
LLM Security vs Traditional Application Security
Many organizations initially assume that existing web application firewalls, API gateways, and cloud segmentation tools are sufficient to secure LLM deployments. While these controls remain necessary, they are not sufficient.
Traditional security focuses on protecting deterministic code paths. LLM security focuses on protecting probabilistic interpretation engines.
Traditional tools inspect structured inputs for known exploit signatures. LLM security tools must evaluate natural language intent and contextual manipulation.
Legacy API protection enforces authentication and rate limits. LLM firewalls must inspect prompts before inference and analyze outputs before release.
Traditional systems assume static rule enforcement. LLM environments require adaptive, runtime policy evaluation.
Understanding this distinction is essential for building effective LLM application security architecture.
Enterprise LLM Application Security Architecture
Enterprise LLM security should be implemented as a layered architecture spanning four tiers.
At the user interaction layer, prompt validation, identity-aware controls, and session management establish baseline protections. Inputs should be scoped to authorized users and filtered for obvious injection patterns.
At the application and API layer, authentication, authorization, rate limiting, and token inspection prevent misuse of model-connected services. This layer ensures that downstream API calls triggered by the model are legitimate and constrained.
At the model and inference layer, AI-aware enforcement becomes central. An LLM firewall or equivalent runtime inspection mechanism should evaluate prompts before execution, detect injection attempts, enforce policy boundaries, and inspect outputs before they are returned to users or passed to automation systems. Behavioral monitoring enables LLM threat detection by identifying anomalous interaction patterns.
At the infrastructure layer, segmentation, DDoS protection, load balancing, and high-availability controls ensure resilience. AI workloads must remain available under high demand and protected from volumetric attacks.
If any layer is omitted, enterprise LLM security posture weakens significantly.
Learn more about our AI Firewall for securing inference environments.
A10’s Arjoyita Roy breaks down how AI guardrails work, why they matter for your infrastructure, and why they are a critical buffer for policy and trust.
How to Evaluate LLM Security Tools
The rapid emergence of AI solutions has led to a fragmented market for LLM security tools. Enterprises evaluating options should apply structured criteria.
First, assess prompt inspection capability. Does the solution detect prompt injection attempts and instruction overrides before inference execution?
Second, evaluate output validation. Can the tool enforce response policies and redact sensitive information dynamically?
Third, examine inference-layer integration. Solutions that operate only at the application perimeter lack visibility into model behavior.
Fourth, consider infrastructure scalability. Enterprise LLM deployments require high performance and minimal latency overhead.
Fifth, ensure integration with existing SOC workflows. LLM threat detection should feed centralized monitoring systems to support incident response.
The best LLM security tools combine runtime inspection, policy enforcement, and infrastructure-level resilience.
Best LLM Security Tools in 2026
In 2026, the most effective enterprise strategies integrate multiple tool categories.
- AI guardrail platforms provide output moderation and response filtering. These are valuable but often limited to content enforcement.
- API security platforms protect inference endpoints from credential abuse and traffic anomalies. They strengthen perimeter controls but lack deep model awareness.
- Cloud-native controls provide segmentation and availability protection. They ensure resilience but do not inspect prompts or responses.
- LLM firewalls operate directly at the inference layer. By inspecting prompts before execution and evaluating outputs after generation, they provide AI-aware enforcement. When integrated with API security and infrastructure controls, they form the backbone of enterprise LLM security.
Explore our LLM Security and AI Guardrail solutions for enterprise-grade protection.
Enterprise LLM Security Best Practices
Here are the top five LLM security best practices as part of our comprehensive guide to LLM security:
- Organizations deploying AI at scale should implement least-privilege access across all model-connected systems. Vector databases and retrieval layers must expose only necessary data.
- Prompt validation and context boundaries should be enforced prior to inference execution. Output validation should occur before responses reach users or automation systems.
- Inference interactions should be logged and monitored continuously. LLM threat detection must be integrated into SOC workflows to ensure visibility.
- Regular adversarial testing and red teaming help identify weaknesses before attackers exploit them.
- Enterprise LLM security is not a one-time configuration. It is an ongoing operational discipline.
How A10 Networks Secures AI Infrastructure
A10 Networks delivers enterprise-grade LLM cybersecurity by combining AI-aware enforcement with infrastructure resilience.
Our AI firewall solutions inspect prompts and responses at runtime, enabling policy enforcement at the inference layer, API security protects exposed endpoints from abuse. High-performance load balancing and DDoS protection ensure availability for AI workloads across on-premises, hybrid, and multi-cloud environments.
By unifying LLM application security with infrastructure-level controls, A10 enables enterprises to scale AI adoption without expanding risk exposure.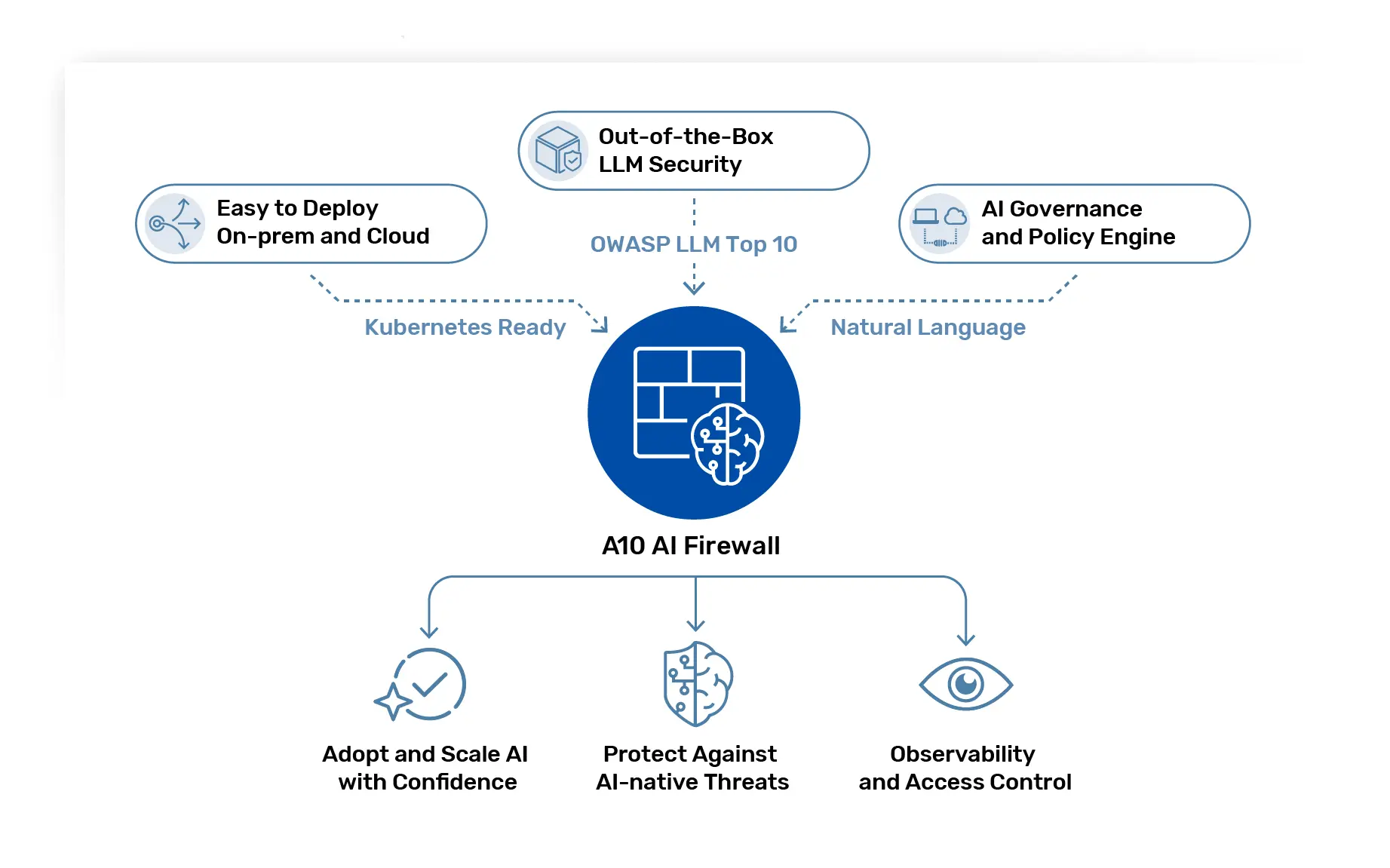
Securing the Future of Enterprise AI
LLM security is no longer optional. As large language models become embedded in core business systems, they must be protected with the same rigor applied to other mission-critical infrastructure.
Organizations that implement layered enterprise LLM security, deploy AI-aware enforcement mechanisms, and integrate LLM threat detection into their security operations will be positioned to innovate confidently.
Protect your AI stack with purpose-built LLM security tools and AI firewall enforcement.
Additional LLM Security Resources
