WordPress Pingback Attack
WordPress is a content management system (CMS) that allows an author to directly edit their blog on a particular website through an easy-to-use graphical interface embedded in the page. The system itself is very feature rich and allows a number of tasks to be automated. Such a task is the “pingback feature,” which allows an author of a blog (let’s call it R) to be notified when the author of another blog (let’s call it T) links to the former blog (R). This paper focuses on the WordPress pingback attack that is named after that particular feature.
So when T adds a link to R’s blog, T’s blog sends a message to R’s blog, notifying them of the event and providing information to the location of the linking blog. As a result, then, R downloads T’s blog to verify that this request is legitimate. This causes a callback request to T.

Users Involved in Pingback
This issue arises from the fact that it is possible for an attacker A to impersonate T’s blog by connecting to R’s blog and sending a link notification that specifies T’s blog as the origination of the notification. At that point, K will automatically attempt to connect to T to download the blog post. This is called reflection.
If the attacker were careful to select a URL that has a lot of information in it, this would cause amplification. In other words, for a relatively small request from the attacker (A) to the reflector, the reflector (R) will connect to the target (T) and cause a large amount of traffic.

Abuse of Pingback to Conduct an Attack
So looking at the bottom line, we have both reflection and amplification, which is an unpleasant combination. Remember all the NTP and DNS reflected and amplified attacks we have been seeing over the past 3 years?
On the good side, this attack is executed over TCP, which makes it somewhat traceable if the “X-Pingback-Forwarded-For” header is not disabled – or it can be traced if the investigator can get access to the logs of the reflectors. TCP requires a 3-way handshake among the parties for a connection to be established so the machine that requests the pingback is reliably recorded in the logs of the reflector.
This is in contrast with NTP and DNS, which use UDP as underlying transport. With UDP, a negotiation between the parties is not needed; instead, a single datagram can carry a complete message (request). This allows the attacker to spoof the source IP address with the one of the victim, which in turn makes the reflector respond back to the victim (which is the reflection part). Usually NTP and DNS provide much larger response than the query itself, which provides the amplification.
Now let’s look in more detail at what actually happens. This section is split into three parts: (1) describing the communication between the attacker (A) and the reflector (R), (2) the traffic between the reflector and the target (T), and (3) looking at the results.
Attacker to Reflector traffic (trigger) pattern
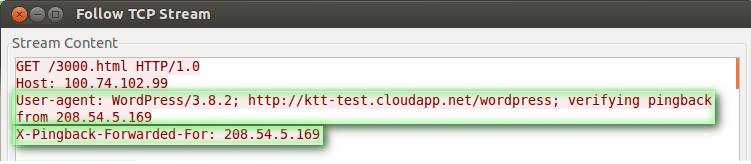
The trigger pattern is fairly straightforward: It’s a simple POST request with specific headers. The payload is just an XML-encoded request. In the following screenshot, you can observe the target IP address of 100.74.102.99 and the requested object 1000.html. Also note that whatever the request is, its length is constant, with a small variation if the URL is longer.
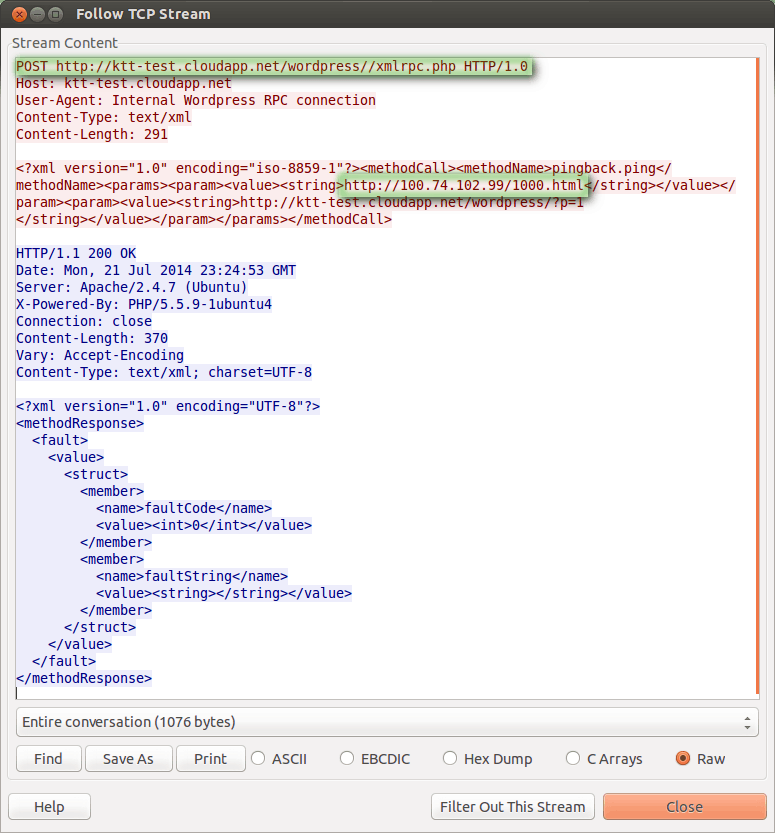
Similarly, the response is XML-encoded and has fixed length.
To summarize: the entire conversation is 1076 bytes – 483 from the attacker to the reflector and 593 in response. As mentioned, those may vary slightly, based on URL length. Also packetwise, they are 5 and 4 packets respectively.
Reflector to Target (attack) traffic
Looking at the effect of the aforementioned request from the point of view of the target, things are very different.
It starts with a fairly constant in length GET request and its headers from the reflector (R) to the target (T). Unlike the fixed length response we saw from the reflector to the attacker, the size of the response is variable and depends on the size of the object requested from the target system.
The following two screenshots display requests against objects of 1,000 and 3,000 bytes.
Request for 1,000 byte object
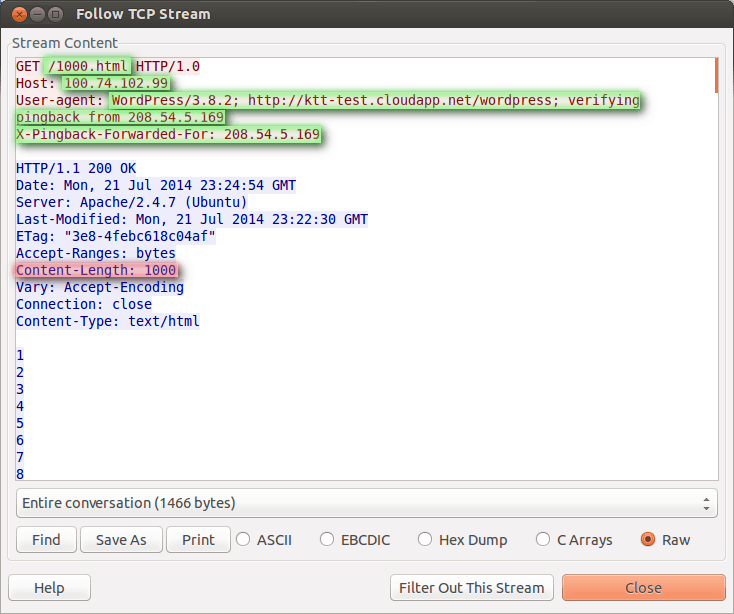
…and respectively 3,000 byte object.
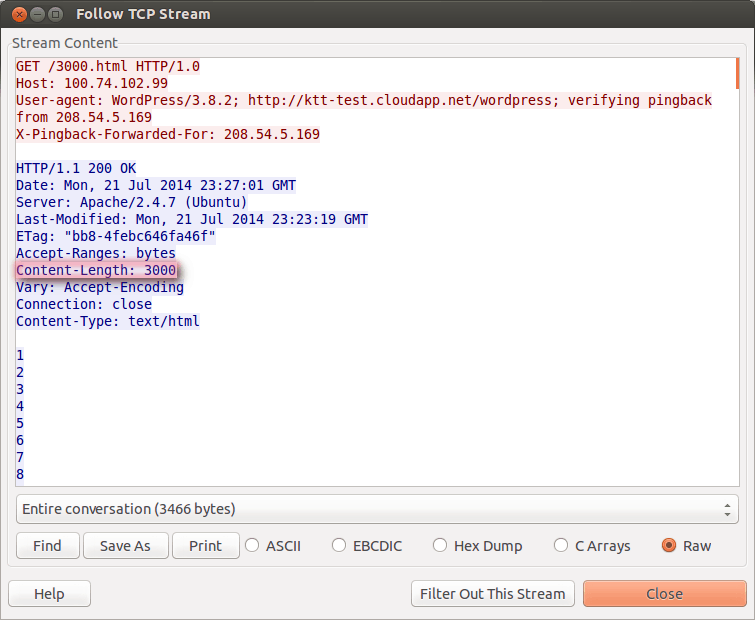
Request for 3,000 Byte Object
Note that the response here is non-constant and solely depends on the choice of the object to retrieve. This can create large amplification based on a single reflector. When multiple reflectors are involved, the attack scales fairly well in disadvantage of the target.
Dissecting the responses further, we see that the reflector issues a fairly constant length request – 195 bytes, more or less, depending on the reflector URL. The response is proportional to the content of the object requested and for a 1,000-byte object, it is 1271; for a 3,000-byte object, it is 3,271 bytes. Roughly, the formula is 271 + object size. It’s a rough formula because packet fragmentation and some other overhead are involved.
The outcome is obvious, though. On the reflector side for the 200-byte request, the response can easily be thousands of bytes – resulting in a multiplication that starts in the 10x, 20x and more.
Bottom line
Looking at the bottom line: the attacker needs to incur roughly 500 bytes to a reflector, which will generate another 200 bytes from the reflector to the target – but then the target will respond with a very large and potentially computationally expensive response to the reflector, in the order of thousands of bytes.
To avoid overloading the reflector, multiple reflectors can be employed to scale up. Thus, the target will have their outgoing bandwidth, and possibly compute resources, exhausted.
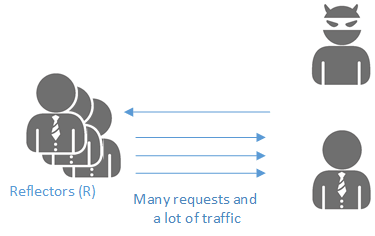
Pingback Abused Using Many Reflectors
A → 500 → R1 → 195 → Target
A ← 600 ← R1 → X x 1,000 → Target
A → 500 → R2 → 195 → Target
A ← 600 ← R2 → X x 1,000 → Target
A → 500 → R3 → 195 → Target
A ← 600 ← R3 → X x 1,000 → Target
Another point to consider is the compute resources tied to the target side. If considering a page that is computationally expensive to produce, it may be more efficient for the attacker to overload the CPU of a system versus the bandwidth of the connection.
Mitigation
Mitigation is somewhat trivial if the right tools are in place. In the attack request (reflector to target), users can observe the “User-Agent” header that clearly states “WordPress.” Under normal circumstances, this User-Agent should not be making requests and at least not at high rate.
Furthermore WordPress inserts a header. This is the “X-Pingback-Forwarded-For”. This header reveals the true identity of the attacker. If a larger number of requests originated by the same IP address, this would also be a good reason to have those requests rejected.
Tools
Apart from the tools used to create a denial of service, one is of particular interest since it can be used to scan a host using multiple proxies – thus potentially making it less visible for an IPS:
https://github.com/FireFart/WordpressPingbackPortScanner
If you are aware of any other tools, please let us know and if possible send us copies.
Conclusion
This is not the first time a CMS, and in particular WordPress, has been used for DDoS or other malicious activity. To a very large extent, this is because WordPress appeals to users that do not have the resources to manage their websites and they often use WordPress to make their job easier. As a result, many users do not have an adequate patch management program or proper monitoring to observe irregularities in their traffic.
Seeing is believing.
Schedule a live demo today.